Terwijl we er al een paar jaar mee te maken hebben is het sinds de vermeende impact op de Amerikaanse verkiezingen een hot topic: het nepnieuws. Onware berichten worden op social media of websites gezet en voordat je “ja maar wacht even” kunt zeggen is het een trending topic en voor veel mensen gewoon ‘het nieuws’.
Facebook heeft al half de schuld gekregen van de winst van Donald Trump en ook Google kreeg er van langs omdat de foute feiten op positie één terug kwamen als mensen een vraag stelden aan de zoekmachine. Met een groeiend deel van de bevolking dat niet sceptisch genoeg is om iets verder dan dat eerste resultaat te kijken levert dat problemen op en dus beloofde Google beterschap.
Er is alleen één probleem, namelijk dat het zelfs voor een organisatie als Google niet makkelijk is om de ‘verkeerde’ resultaten te verbannen. Neem het opstootje dat vorige week plaatsvond omdat het eerste zoekresultaat voor de ‘popular vote’ (hoeveel Amerikaanse burgers echt op Clinton hadden gestemd) foutief aangaf dat Trump ook daar gewonnen had, terwijl het al duidelijk was dat dit niet klopte. Het bleek een blog dat maar gewoon cijfers aan het verzinnen was.
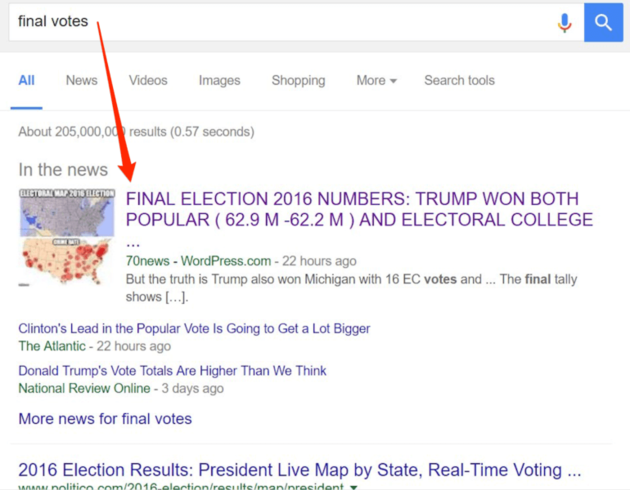
Inmiddels is het blog verwijderd en heeft Google ook al laten weten de financiële kraan dicht te draaien voor dit soort blogs, maar het pakt het probleem niet bij de wortel aan: hoe zie je of iets waar is? Het probleem is terug te leiden naar 2004, toen Google niet alleen nieuws van bekenden door mensen gecheckte nieuwssites in hun ‘in the news’-vlak bovenaan zoekresultaten toeliet, maar een algoritme het meest ‘kloppende’ artikel liet zoeken. Vanaf dat moment was manipulatie van de feiten makkelijker dan ooit.
Google schijnt van plan te zijn dat terug te gaan draaien en weer een gecureerde selectie aan nieuwsbronnen met ’top stories’ te laten zien, zodat random blogs niet meer kunnen opduiken bij het eerste het beste zoekresultaat. Dat is een eerste stap, maar het lost het probleem van de zoekresultaten an sich niet op. Die kunnen nog steeds een verdraaid beeld van de realiteit weergeven en daar is geen algoritme tegen opgewassen, althans geen algoritme dat nu wordt gebruikt.
Er zit vermoedelijk niks anders op dan ouderwets mensen in dienst te nemen die de data kunnen bekijken van zoektermen die opeens veel voorbij komen en de voorkeur aan factchecking sites te geven voor het antwoord of zelfs de websites te benadelen die nepnieuws naar buiten brengen. Hoe dan ook, het gaat ze in de problemen brengen, want dan is “censuur!” snel geroepen en moet dat brandje weer geblust worden, zoals Facebook al ondervonden heeft. De oplossing is er dus op dit moment nog niet en zit er voor ons als zoekmachinegebruikers niks anders op dan verder kijken dan onze neus lang is.